type-explorerというTypeScriptの型を展開・閲覧出来るVSCode拡張を作っている
作っている
ので、宣伝も兼ねてどんなものかとかをつらつら書こうかなと思い立ったのであった
モチベーション
最近の開発でGraphQLを使っていて、GraphQLのスキーマから自動生成した巨大な型を扱っているうちに以下のようなつらい気持ちを味わうようになった
- tscのエラーメッセージで巨大な型は省略されてしまう
type<T> = ...のように Type Aliasで生成された型が結局どんな型なのかわかりにくい- 例えば変数に束縛して suggestionから見る、みたいにして型情報を探る、みたいなことをするのはかったるい
んで、
- 既にそういう課題を解決してるツールがないかと思って探してみたけどなかった
- 最近VSCodeが Tree View API なるものが使えるらしいというのを知っていた・TypeScriptのCompiler APIを使えばできそうな気がする
という気持ちになり、作り始めてみた、という流れ
出来ることとか
リポジトリはこちら:
大体こういった体験を提供する感じの拡張。
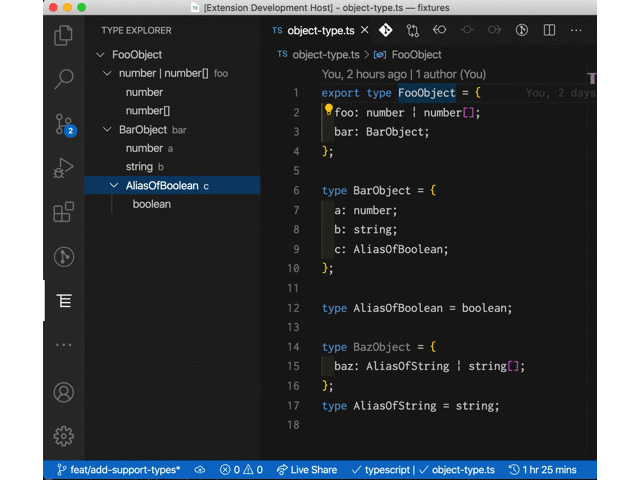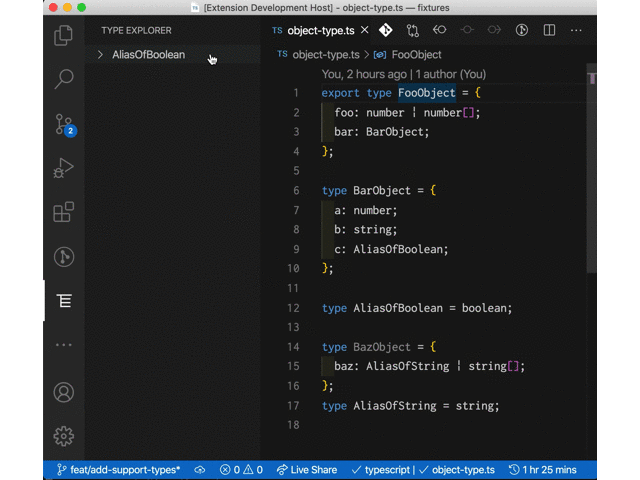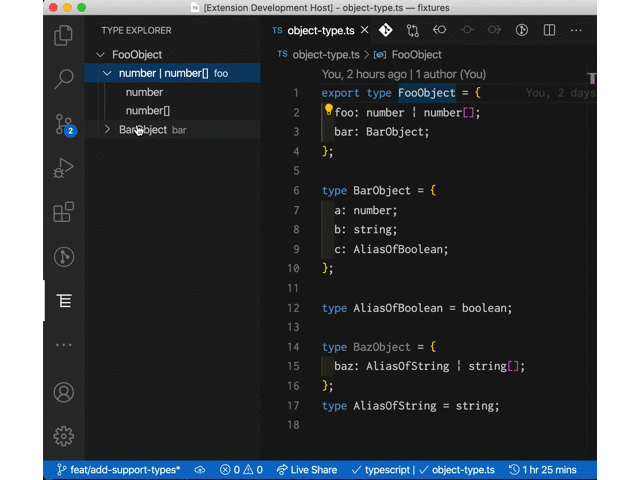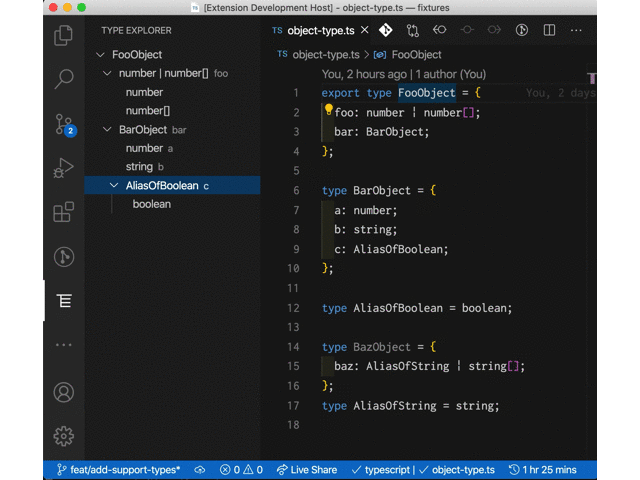
現時点ではカーソルが移動するたびにツリービューを再構築するようにしてるけど、ツリー側は固定させて型をクリックしたらエディタ側でその定義元にジャンプさせるとかもありかなとか考えていたりはする
まだ試作版もいいとこなのでそのへんは試行錯誤する予定
技術的な
TypeScriptのCompiler APIで ts.Node を走査して型に関する情報だけ↓のようなTreeNode型のオブジェクトとして抽出・得たTreeNode型のオブジェクトを元にVSCodeのTreeViewにぶち込むというだけ
export type TreeNode = {
id: number;
variableName: string | undefined;
typeName: string;
children?: TreeNode[];
};
コンセプト的にはほんとそれだけ
といっても ts.Node を走査するという実装を網羅的に実現するのは大変だし、VSCode側で編集されたソースコードに型情報をリアルタイムに追従させるのも大変そう(まだちゃんと試してない)
まあそれでも全く手も足も出ないほどじゃなさそうで、実際にやってみたらひとまず最低限動くまでは漕ぎ着けられた
課題としては現状、型情報を網羅的に対応することよりもVSCodeで編集されたソースコードのリアルタイム反映がしんどい感じ
いろいろ考えた結果、やるとしたら結局ts.LanguageServiceHostとVSCodeの編集内容を繋ぎこむ処理を自前で実装し、ts.LanguageSeriviceを自前で立ち上げるなのかなと思う
(tsserverにコマンドを独自拡張出来てエディタからそれを呼び出せると一番楽なんだけどtsserverに拡張の仕組みはないので無理っぽいという辺りで無念になったりした)
今後
とりあえず自分で普通に使いたいので、個人的に実用出来そうだなラインまでは作りたい気持ち(気持ちだけ)
目下は変数にアサインしたときに推論される型情報を見れるようにする実装がかなり苦しそうというのが悩みポイント でもこれを解決できると一気に使い心地が良くなるだろうなと思うので頑張りたいところ
マイクロサービスなアーキテクチャで権限制御を考えている
最近業務で権限制御を設計しているので調べたり考えたりしているのでメモ
前提
- 現存してるアプリケーションについて
- これから作るアプリケーションについて
調べたこと(基礎編)
まず自分自身が権限制御について詳しくないので設計パターンを調べたり考えたりした
Computer security model(Wikipedia)
Computer security model - Wikipedia
典型的な権限制御パターンが列挙されている。
全部読もうかと思ったけど英語なので時間かかる・Webアプリケーションとして利用できるパターンはこの中の一部っぽい雰囲気だったので深追いはしてない
アクセス制御(Wikipedia)
アクセス制御に関する基本的な概念がまとまっている
機密性・完全性・可用性という情報へのアクセス制御の基本的な要件や、認証・認可・監査というアクセス制御を実現するためのステップ、トークンに基づいたアクセス制御など一通りのアクセス制御に関する情報がまとまっている
個人的には↓の内容は知らなかったのでなるほどになった
- アクセス制御において主体と対象をそれぞれsubject/objectと称すること
- 「機密性・完全性・可用性」という概念
- 認証・認可だけでなく監査もアクセス制御として考えるべきものであること
オペレーティングシステムのアクセスコントロール機能におけるセキュリティポリシーモデル
https://www.ipa.go.jp/files/000002266.pdf
IPAの資料
「OSの」という題目だけど、アクセス制御についての要件が書かれていて一般論として参考になる
セキュアOSでアクセスコントロールを実現するためにはリファレンスモニタ・セキュリティポリシーモデルという概念が明確に定義・実装されている必要があるという内容があり、これは考え方としては一般的なWebアプリケーションにも流用できそうだなとか思った
リファレンスモニタというのはコンピュータ上の全てのobjectへのアクセスをコントロールするもので、subjectのobjectへの操作は全てこのリファレンスモニタを通さなければならない、というもの
Webアプリケーションで実装する場合全てのリソースへの操作を集約するというのは簡単ではないのでそのまま流用は難しいが応用したいなとは思う
例えば典型的なライブラリだと実装者が明示的に「このリソースへのアクセスが許可されているか?」を判定するコードを各所に記述するパターンが多い ( cancancan、casl、casbinなど)し、実際のところ単機能のライブラリとして提供できる範囲だとこれが落とし所だろうから、それを踏まえてアプリケーションの実装レベルのアーキテクチャを考えるときにリファレンスモニタの考え方を参考にする、になるのかな
セキュリティポリシーモデルは、「どの主体が、どの対象物を、どのように操作できるのか」を定義し、この定義されたセキュリティポリシーは数学的に検証可能であることが要求される(必ずしも実現可能ではないが)、というもの
資料内でセキュリティポリシーモデルの典型例を紹介してくれており、Bell-LaPadulaのような歴史のあるモデルからRale Base Access Control(RBAC)のようなWebアプリケーションでもよく利用されるパターンまであるので大変ためになる
(各モデルが数学的に検証可能かどうかについて言及がないので自分は結局「セキュリティポリシーモデルが数学的に検証可能であること」についてどういうことなのかピンとは来ていない)
Webアプリケーションでは殆どのケースでRBACあるいはその発展型のAttribute Base Access Control(ABAC)で賄えるので各セキュリティポリシーモデルを理解するのは直接的に役に立つわけではない感じもする
ただ、仮に良いライブラリがなくて自分でRBAC、ABAC相当の実装を記述しようと思ったときにこの 「どの主体が、どの対象物を、どのように操作できるのか」を定義し、この定義されたセキュリティポリシーは数学的に検証可能であることが要求される という点を前提にしてコードを書くと品質を高められそうだなとは思う
それらの実装に対してユニットテストを書く際もProperty based testingや形式手法を用いることによって「数学的に検証可能」という点を意識しながら書けるのかも?とかとか
調べたこと(権限のアプリケーションレベルでの設計)
実装レベルの設計を考えたいのでその観点で調べたこと
業務システムにおけるロールベースアクセス制御
RBACの解説とDB設計・Javaによる実装例が書かれている
実装例よりもその手前のRBACを実際に実装に当てはめるときに気をつけるポイントが参考になった
ロールとパーミッションは別物であることを意識するべき・組織とロールを結合させてはいけないなどの考え方は意識してないと漏れそう
アプリケーションにおける権限設計の課題
基礎のおさらいから実装面でどうすれば?という点まで言及されている
実装を考える場合に権限を「管理」「判断を下すサポート」「判断を下す」「適用」というパーツがあり、これらの責務を明確にしながら実装すると良いという話をコードやモノリシック・マイクロサービスアプリ上での責務分離の例を交えながら解説してくれている
IAMとは(AWSドキュメント)
アプリケーションにおける権限設計の課題 の記事でも言及されていたが、IAMは大抵のWebアプリケーションにおいて要件の最大値として考えておけばいいと思う
調べ始める前にもIAMをベースに考えればいいかなとか思ってはいた
実際のアプリではパーミッション(IAMで言えばポリシーステートメント)はハードコードで十分だと思うのでそこは要件から落とす、などすればよいのかなと考えている
マイクロサービスで管理画面が乱立する問題と対策
タイトル的に関係なさそうに見えるけど中では認証・認可の話題が殆どだったのでめっちゃ参考になった
マイクロサービスアーキテクチャにおいて権限管理をどういう方針で実施し、どんな課題を解決(しようと)したかが書いてある
今回検討してる内容とまさにピンポイントで合致する話題だったので大変ありがたかった
権限を中央に集約するか各アプリケーションで持つかはこの記事を書いてる今も悩んでいることなのでまだまだ考えたいところだがこの事例は思考の起点にさせてもらっている
余談だけど社内で利用言語・FWが統一されてると一個ライブラリ作れば簡単に横転できていいな〜とは思ったりした
調べたこと(ライブラリ編)
Node.jsで利用できる権限制御ライブラリを探した
casbin
ロゴがGopher君だけどGo言語以外にも展開されている
Supported Models を見るとABACに対応してるので検討しても良かったがDSLによって権限を記述するのがちょっと嫌だった・可能ならフロントエンドでも使いたかったがcasbin.js がかなり怪しげだったので見送り
role-acl
メソッドチェインで権限を記述できてTypeScriptフレンドリーな感じのAPIで良さげ
ただ、 Role, Attribute and conditions based Access Control for Node.js とあるようにNode.js向けっぽいので惜しい
casl
Features に書いてある Isomorphic TypeSafe Tree shakable Declarative の時点で気に入ってしまったし、 Versatile の項目にある通りABACやれまっせとのことなので要件としても満たされる
実際に書いて試してみているところだが、やりたいことを実現するには必要十分でSPA向けのコンポーネントまで提供されてて至れり尽くせり
今の所本命
とりあえず現時点で調べたことをガーッと並べただけなのでオチとかはない
前提の欄を設けてみたけどいらなかったかも、と最後まで書いて思ったけどまあ供養ってことで残しておく
caslの使い方とかAuth0の使い方とかそのうち気が向いたら書きたい気もする
全員リモートの環境で「むきなおり」のワークを実施したので書き残す
昨今の情勢でうちの会社の開発部門は3月からほぼ全員がずっとフルリモートで働いている
そんな中だけど、1Qが終わったのでキリも良いからと普段の振り返りではなく「あるべき姿との差分を取るという目的で」むきなおりという手法でチームを振り返ってみた
この手のチーム活動系のワークをフルリモートでファシリテーションしたのは計画などの定常MTG以外では初めてだったのでどう実施したかやら感想やらを書いてみようと思う
むきなおりとは?
自分たちがあるべき姿というのを改めて確認し、今あるべき姿に進んでいけてるか?という観点で振り返るという手法
あるべき姿と現状をチームメンバーで出し合って、差分を取り、差分を埋めるためにどうすればいいか?を計画するのがこのワークのゴールになる
*むきなおり参考記事
どうやったか
↓のようなスプレッドシートを作成して、全員でこれに書き込んでいくことで実施した
この手のワークショップでは「いっせーの」で自分の意見を出すまでは他の人の考えが見えない方がベターだけど、その点をうまいこと解決する方法は見つけられていないのでこのような形にした
進め方自体は定番通りで、アウトプットのフォーマットがふせんじゃなくてスプレッドシートになっただけ、という形
時間もかかるMTGなのでなるべく簡単に書ける・ツールの使い方で困らないようにしたい・サマる作業を手間を掛けず、と考えたら普段使い慣れてるスプレッドシートを使う、という選択になった
結果どうだったか
割と上手く回ったと思う。チーム的にも有意義だったというFBだった
リモートでのファシリテーションでは表情が見れないので「場の雰囲気」に合わせた調整が出来ないというのはやはり難しいが、もう丸2ヶ月近くフルリモートでチームでの意思疎通をやってきているのもあってか、盛り上がらない(意見が出ない)・場が硬直するといったこともなくスムーズに進んだと思う
自分はずっと対面でやる以外ありえない、ぐらいに思っていたが、リモートでもやれなくもない、ぐらいに意見を変えようとは思った
この時間でチームメンバーの思っていることや普段と違った切り口での課題提起に繋がったし、自分自身開発メンバーとして改めて気付かされたこともあり、単純にむきなおりをしたことによる恩恵もバッチリ受けられたと感じられた
チームとしてもファシリテーターの立場の自分としても、あるいは開発メンバーの一員としての自分としても得るものがあったのでいい時間だったな、という感想
また今度は半期の終わったあとにやろう、という話も出ていて、そのときにチーム・プロダクトがどうなっているかも楽しみ
わたしのコードりれきしょ
他の人が書いてるのを見かけて楽しそうだったのでやってみた
- 高校2年生ぐらいの頃にコミケに本を出そうって友達がいてその告知用サイトを作った。(当時友達に内輪用サイト作る人、自分のコンテンツ発信用サイトを作る人などがいてその影響を受けた)。CSS2とかって単語があったのは覚えてる。PHPもHTMLのテンプレートを共通化するために使ったりした。まあつまりサイト制作
- 大学の講義でCで二分探索木(なんもおぼえてない
- 大学の講義でJavaでなんかのCLI(なんもおぼえてない
- 大学の講義でPerl/bashで電卓(なんもおぼえてない
- 大学の講義でPHPで就活の何かを管理するためのwebサービス。5人チームで半期かけて死ぬほど苦労した(週50時間ぐらい稼働してたときもあった気がする)。要件定義からリリースまでやるのを半年かけてやる講義できついから覚悟しろよって言われてたけど本当にきつかった。XAMPPでPHP環境作ってやってたけど環境構築死ぬほど大変だし、自分のマシンでは動くのに人の環境では動かない、とか、ソースコード管理がないのでDropbox使ったり、人力マージしたら動かなかったり、あと確か要件定義書のようなやつ(UMLとかも含め)を死ぬほど書いてそれを全部印刷して提出とかしてた気がする。ちょっとした分厚い本ぐらいはあったはず。とか、とにかく辛かった
- 研究室でPerlつかってmecabで形態素解析したりした。何やったかは全て忘れた、ボスに言われるがままにやっててなんか自分で考えた記憶がない。扱った日本語データがXMLだったんだけど、当時何も知らなかったので正規表現でXMLをパースすることを試みてXMLの階層構造を正規表現で扱うのは無理じゃんどうしようもないってなって何かを妥協した記憶はある。DOMTreeにしてvisitorパターン、とか知らなかったからしょうがないね。GitHubに上げてあるけどPrivateにしてあるのでリンクは省略
- 就職したてwebの部署に配属されてお問合せフォームをVBScriptで作った。毎月ぐらい定常的にある作業・でも簡単、ということで新人に毎回やらせてるらしい。なるほどかんた・・・いや何もわからん・・・ってなりながら四苦八苦して書いたりしていた気がする
- フォームに要素追加する機能をVBSで動いてるサービスに入れるとか、何かの監視機能をVB6で書いたりした記憶はある。この辺何も覚えてない。
- なんかの設定画面のリニューアル。先輩がバックエンド、自分がフロントエンドをjQueryで動的にフォームを生成したり消したりするようなのを作った。ここで色々フロントエンドを作るということについて知ることが出来たのが多分フロントエンドエンジニアとしてやっていくことになったはじめの一歩だったと思う。あと今になって思うと、当時SPAとか誰も知らなかったはずだし他の殆どの機能はMPAでVBSのテンプレートの中にロジックがあるっていう昔ながらのPHPみたいなプログラムだったのに、サーバー・フロントを分けてその機能はSPAとして作るってしてたのすごいなあと今書いてて思った。
- 9のときに先輩と自分の間でトライアルでgitを使い始めてて、そのgitを社内全体で使おうって活動をしたりした。そのあとバージョン管理やデプロイのフローが破綻してたので、整備してgit使ってpull→デプロイらへんを半自動化する何かを用意した気もする。
- 多分C# .NET MVC3のサービスとかにこの辺から入ったりしてた気がする。何作ったかは忘れた。
- 他のチームに、200環境に半年かけて手動デプロイするという地獄を観測したのでそのデプロイの自動化ツールを作った。この頃にはjsどっぷりでes6だasync/awaitだみたいなのに染まってたのでランタイムnode0.12.7らへんでbabel使ってダウンパイルみたいなことして作ってた気がする。社内にnode分かる人いなかったし、社内で新しいものについてはC#でやる流れがあったのをガン無視したのは今の自分なら全力で止めそうで笑う(当時の自分はC#でCLI作れると思ってなかった(!?)からよくわからないままnodeを選んだ記憶もある)。やってることとしてはFTP繋いでファイルを上げるってだけ。結果デプロイは作業時間としては30分、検証とかその手のバッファみつつ間を空けながら2,3日でやる、というフローで出来るようになった。世界の不幸が一つ減ったことに満足を得たりしていた
- 多分11,12くらいの時期からちょこちょこgithubにちょっとしたものを作ってとりあえず上げておく、みたいなことをするようになっていた。sisisin-sandboxというorganizatioを作ってここに何でもかんでもアップしてた。reactやらexpressチュートリアルやったりelectron触ったりexpressで単純なフォームでソーシャルブックマーク出来るみたいなやつを作って自宅のPCをサーバーにしてホストしたりwindows環境用によく使うVagrantfile書いたりwakatimeの実績をtwitterに流すバッチ書いたりアニメ実況向けのtwitterクライアント書いたり何か思いついて形にならないまま放置(何を作ろうとしたのかすら思い出せない)したり、社内向けにgitの勉強会用のgitリポジトリ作ったり、TDDBCで使おうとしたrubyとrspec試した形跡があったり、twitterのフォロワーから相談されてtypescriptのユニットテスト環境作ったり色々。
- 会社のサーバーサイドがVBSで、その中でVB6で書かれたCOMコンポーネントを利用していて、このCOMコンポーネントを脱却したいという話があった。COMコンポーネントをC#で使う方法があって、これを使ってCOMの機能をC#でラップしてそこを介してどうこうしよう、とか、その機能をマイクロサービス化したら良いんじゃないかとかを調べたり考えたりしてた。とりあえずCOMをC#から動かしてAPIとして呼べるところまでは作ったりはした。活用されることはなかったけど。
- 現職に入って最初に試しにscalaでRESTAPIの1エンドポイント作ることになって何もわからなくて詰んだ
- typescript+angularjsでダッシュボード画面作った。個人でreact触ったりしてたけどまともなSPAを業務で作るの初めてだったのでかなり苦労した気がする
- レポート系の画面を作ったり直したりしてたっぽい
- コミティア用にサークルチェック結果をcsvにするスクリプトを書いたりした
- なんかよくわからないけどscalaでそこそこ巨大な修正してたっぽい。プルリク眺めてるとほとんどフロントばっかやってたはずなのにどうやってscala書いたんだこの人・・・?
- gulpfileがcoffee scriptで書かれてたのをjsにしてgulp-typescriptじゃなくてtsc直たたきにしてパフォーマンス改善したりみたいなことやってた
- Angular2が出る出ないみたいな話で試したりとかしてたはず。新規サービス立ち上げのときにRCだからって使っていいでしょって選んだら思ったよりぶっ壊れでごめんになったりもした
- 広告計測サービスの計測タグのe2eテストがやたら落ちてるとかの対応したりカバレッジ出せるようにしたりしてたっぽい
- tscのoutFileでconcatしてたangularjsのビルドをes modulesに置き換えたりした。tsのcompiler apiつかってast走査してimport文を生成・挿入するスクリプトを書いてゴリッと置き換えたりした
- tsdという型定義パッケージ管理ツールを撲滅してた。typingsに飛びつかないでnpmに集約されてからやってるの偉いってなってる
- プロジェクト共通で使ってるURL基底クラス部分が広告の計測サーバーやその他諸々で問題があったので置き換えるみたいなことやったらしい。このへんでURLエンコードとはってなって書いた気がするこの記事、未だにちょこちょこLGTM付くので良かったなとか思う
- coffee scriptで書かれてた計測タグのe2eテストをjs化したり、会社の納会で1人ハッカソンしてユニットテスト側もjs化したりしている
- コミティアやコミケの予定をスクレイピングしてGoogleカレンダーに入れるバッチ書いた
- 次の日の予定に気づかずに寝坊遅刻みたいなのがちょこちょこあったのでGoogleカレンダーの次の日の最初の予定を取ってきてtwitterでメンション飛ばす機能を作った。マジで便利だった
- SafariのITPが来たのでその対応のために計測サーバーや計測タグの対応をしたりしていた。どうやってcookieつければいいかとか1st cookie使ってどうこうとかタグの発火順とかを設計したりして大変だった
- 開発合宿で広告計測サービスの管理者用画面のAngular化を7割ぐらいやった。楽しかった。
- CI職人やってるっぽい。フロントのみの変更のときにscala系のタスクが走ると厄介なので直したり、CIで使ってるDynamoDBとかのイメージを差し替えたりscalaの本番用ビルドをS3に上げる部分いじったりscalaのCIパフォ改とかいろいろ。
- 広告計測の集計結果をs3->gcs->bqと突っ込むようにする作業をしたりしていた。s3 to gcsでtransferサービス使うときにファイル数が多すぎて不安定になって障害起きたりして大変だった
- cloudfirmation触る機会が増えたりしてcloudformを試したり、cloudformに機能追加したりした
- react/reduxのプロダクトを立ち上げたりしていた
- storybook+reg-suitの環境作ったりしてビジュアルリグレッションテストを搭載
- 開発合宿でslackをtwitterふうに閲覧できるクライアントを作ったりした。これもreact/redux。サーバーはexpress
- 蔵書管理アプリ をtypelessで作った。スマホカメラでバーコード読んで借りる返すができるようなやつ
- typelessに色々コントリビュートした。型定義怪しいの直したり、バグっぽい挙動の修正方法提案したり、middleware実装しやすくする方法を作ったり、RegistryやEpicのユニットテストしやすくしたり、EpicでPromise受け付けるようにしたり
- typeless触ってて見つけたtypescriptのLanguageServiceのバグを直した
- railsで集計処理っぽいクエリを書いて地獄を味わう
- railsで重いクエリと戦い敗北してredisにキャッシュすることで逃げたりした
- mackerelの監視環境を整えたりした
- railsのバッチでメモリプロファイラ使ったりして重い処理を探して直したり
- react-routerで型安全にroute定義出来るように試みたり
- grqphql叩くやつ書いたりしている
細かく書いてたら長くなってしまった
ISUCON9予選参加した
反省会。
チームについて
@kadokusei , @watiko と3人で sisisinと愉快な仲間たち チームとして参加。
kadokusei がインフラ、 watiko・自分がアプリとかボトルネック調査を担当
自分の覚えてる範囲でやったこととか書き残しておきます
最終的に出来たこと
/users/transaction.jsonの外部API呼び出しのキャッシュ- redisに
/statusの結果をキャッシュしておいてそこから引く処理を入れた /initialize時に初期データから取得できるステータスを全てキャッシュに突っ込んだ
- redisに
- DBインスタンスを分けた・DBインスタンスにredisを載せた
categoriesテーブルのデータをメモリにキャッシュ- 最初から全部乗せるのはテーブル構造が地味に複雑だったので諦めて、結果をメモ化するにとどめた
- items,transaction_evidences,shippingsに適当にインデックスをはった
やろうとしたけどダメだったこと
- appの複数台構成
/users/transaction.jsonの外部API呼び出しの並列化- こんなに言語によって難易度差出るやつは想定解法じゃないんじゃ?って疑問に思ってドキュメント見たらキャッシュできそうだったので方針切り替えた
調べて気付いたこと
- datadog APM使って各種エンドポイントとそのどこに時間がかかっているかの調査
/users/transaction.json,/items/:item_id.json,/new_items.json辺りが重い
- DB全然時間かかってなさそう
/users/transaction.jsonはN+1に目がいったけど実際はAPI呼び出しがめっちゃ時間食っているcategoriesやusersテーブルの呼び出し回数がやたら多い(が、時間はかかってない)
つらかったこと
- 初手アリババクラウドから身分証明書提出を求められるダイアログが出てしまって運営の対応待ち。
- 10:30ぐらいまで何もすることがなかったのでマニュアルを読んでいた。
- せめて
/docsだけでも最初に配布しておいてもらえればまだ良かったんだけど・・・
セキュリティリスクがっていわれてインスタンス立ち上がらなかったイエーイ #isucon
— しめにゃん (@_sisisin) September 8, 2019
- デプロイ周り整えるのに時間食いすぎた
よかったこと
- 準備してたところはちゃんと出来た
- redis用意、datadog apm用意、初期のconfig作成など
- ローカル環境整えたのは便利に活用できた人もいた(自分は
/users/transaction.jsonの動かし方がわからなかったのであまり活用できず。。)
感想
最終的に目の付け所は悪くなかったと思ってるんだけど、自分の地力不足を感じた
たかがインデックス貼るスクリプト書くのに30分とかかけてて雑魚乙って感じになってしまった、もっと上手くなりたい・・・
あとデプロイ周りは書いて終わりじゃなくてデプロイしてベンチするところまでちゃんとやりたいとか、ボトルネック調査もっと上手くやりたいとか色々ありつつ
初参加だったけど手応えはあった気もする
ただちょっと微妙な点として、普段こんなに生のインスタンス触らないから練習負荷が高いのがなんともなあという気持ちがちょっとだけあったりも。
結構悔しいので来年もまた頑張りたい所存
Aurora ServerlessとECS Fargateで動くRailsアプリのクエリチューニングをした
tl; dr
- Aurora Serverlessの場合はスロークエリログ有効化設定がAWS上にある
- DataAPIを有効化すればクエリ叩き放題で最高
- チューニングのためのはじめの一歩として、パフォーマンス計測のための環境整備をインフラやアプリに合わせて適宜構築するのが大事
結果としてやったことはただ単純にslow query logを有効化して該当のクエリをexplainして直しただけ
前提
- ECS Fargate
- Ruby on Rails
DB
- Aurora Serverless
- MySQL 5.6
インフラの構成管理にはAWS CDK経由でCloudFormationを利用
準備
まずスロークエリログを見たい or APMでアプリのボトルネックを見たい、というところからスタート
スロークエリログ有効化の方が手っ取り早いし多分クエリが遅いはずだと思ってたのでひとまずスロークエリログから着手した
スロークエリログ有効化
Aurora Serverlessを利用している関係で直接MySQLのログを見ることは出来ない
CloudWatchLogsに吐かせる設定がコンソールやCFnなどから出来るのでその設定をした
参考:
Aurora ServerlessでログをCloudWatch Logsへ出力可能になりました | DevelopersIO
*aws-cdk@0.20.0 を利用(古いのはご愛嬌)
const dbParameterGroup = new rds.ClusterParameterGroup(this, 'DBParameterGroup', { family: 'aurora5.6', description: `Parameter Groups`, parameters: { slow_query_log: 1, }, }); const cluster = new rds.cloudformation.DBClusterResource(this, 'Database', { dbClusterParameterGroupName: dbParameterGroup.parameterGroupName, // 中略 });
スロークエリログで何度も叩かれてそうな上に遅いクエリを見つけたのでとりあえずそいつをexplainしたいということになったので今度はその準備をすることに。
DBインスタンスにクエリを実行する
結論としては、Aurora ServerlessのDataAPIを有効化してAWSコンソールから直接クエリできるQueryEditorを利用した
参考: Amazon Aurora ServerlessでManagement Consoleからクエリが実行可能になりました | DevelopersIO
他の選択肢はこんな感じだった
- ecs-cliのrunコマンド経由でrails runnerを利用してモデルのクエリをexplainする
- ECSタスクを毎回立ち上げてクエリしてその結果をCloudWatchLogsで確認、という流れなので死ぬほど面倒
- gatewayサーバー立ててssh
- EC2立てるだけっちゃだけだけど、その辺手慣れてるメンバーがチームにいないので微妙に腰が重かったしお金もかかる
- ALBで一時的にVPCトンネルをつくる・・・?
- 風のうわさでそういうことが出来ると聞いたけどよくわからなかった
結果
ここまででスロークエリを探してexplain出来るようになったので、該当のクエリを見てみたらwhereされてないサブクエリの結果セットが80万行とかになっていたのが原因ということが判明
適当にモデルのクエリを調整していい感じに速くなった。めでたしめでたし。
APMについて
チューニングしたときには活用しなかったけどちょろっと調べたり動かしたりしたので一応メモ
あがった選択肢
- NewRelic
- gem入れるだけで動かせてお手軽
- ECSの料金体系についてドキュメントがなく、問い合わせて見積もりもらわないとわからないので会社員的に地味に辛め
- *そのぐらいポンッと使わせてくれない会社が悪いという説もある
- AWS X-Ray
- ECSの場合エージェント用のタスクを立ち上げる必要があるのでNewRelicに比べると導入めんどい
- ドキュメントにもRailsのサンプルがなく、多少試行錯誤しそうだったので動かして見るところまではまだやってない
- DataDog APM
- NewRelicよりは安そうだった
- あまりちゃんと調べてない
感想
Aurora Serverlessが便利だった(こなみかん)
実はこのクエリチューニングはチームで1日時間をとってISUCON大会と称して合宿したときの成果で、それはそれで良かったという話もあったり。
スロークエリを探しつつAPMをアプリ得意な人が準備したり、explainするときに何見ればいいのかとか横からアドバイスもらったりしながらワイワイやれて楽しかった。
うちのチームは様々な事情でバックエンドエンジニア不足のためにこの手のタスクの進みが悪いので、こうやってISUCON大会してガッと進められたのはめっちゃよかった